


认识 OpenAI“多模式”GPT-4V 的两位开源挑战者

OpenAI 的 GPT-4V 被誉为人工智能领域的下一个重大事件:一种可以理解文本和图像的“多模式”模型。这具有明显的实用性,这就是为什么两个开源项目发布了类似的模型 - 但也有一个黑暗的一面,他们可能在处理上遇到更多麻烦。以下是它们的堆积方式。
多模态模型可以完成严格的文本或图像分析模型无法完成的任务。例如,GPT-4V 可以提供更容易展示而不是讲述的说明,例如修理自行车。由于多模态模型不仅可以识别图像中的内容,还可以推断和理解内容(至少在一定程度上),因此它们超越了显而易见的范围,例如,建议可以使用图中冰箱中的成分来准备的食谱。
但多式联运模式带来了新的风险。OpenAI 最初推迟了 GPT-4V 的发布,担心它可能会在未经图像中的人物同意或不知情的情况下被用来识别图像中的人物。
即使现在,GPT-4V(仅适用于 OpenAI 的ChatGPT Plus计划的订阅者)也存在令人担忧的缺陷,包括无法识别仇恨符号以及歧视某些性别、人口统计和体型的倾向。这是根据 OpenAI 本身的说法!
打开选项
尽管存在风险,公司——以及松散的独立开发者群体——仍在继续前进,发布开源多模式模型,虽然能力不如 GPT-4V,但可以完成许多(如果不是大多数)相同的事情。
本月早些时候,来自威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学的研究人员团队发布了LLaVA-1.5(“大型语言和视觉助手”的缩写),它与 GPT-4V 一样,可以回答问题关于图像的提示,例如“这张照片有什么不寻常的地方?” 以及“来此旅游时需要注意哪些事项?”
LLaVA-1.5 紧随Qwen-VL的脚步,Qwen-VL 是阿里巴巴团队开源的多模态模型(阿里巴巴将其授权给每月活跃用户超过 1 亿的公司),以及 Google 的图像和文本理解模型包括PaLI-X和PaLM-E。但 LLaVA-1.5 是首批易于在消费级硬件(显存小于 8GB 的 GPU)上启动和运行的多模式模型之一。
在其他地方,Adept 是一家构建可以自主导航软件和网络的人工智能模型的初创公司,它开源了一个类似 GPT-4V 的多模式文本和图像模型,但有一些不同。Adept 的模型能够理解图表、图形和屏幕等“知识工作者”数据,使其能够操纵并推理这些数据。
LLaVA-1.5
LLaVA-1.5是LLaVA的改进版本,几个月前由微软附属研究团队发布。
与 LLaVA 一样,LLaVA-1.5 结合了一个名为“视觉编码器”的组件和 Vicuna(一个基于 Meta 的Llama模型的开源聊天机器人),以理解图像和文本以及它们之间的关系。
原始 LLaVA 背后的研究团队使用 OpenAI 的ChatGPT和GPT-4的纯文本版本生成模型的训练数据。他们为 ChatGPT 和 GPT-4 提供了图像描述和元数据,促使模型根据图像内容创建对话、问题、答案和推理问题。
LLaVA-1.5 团队更进一步,扩大了图像分辨率,并将来自 ShareGPT(用户与 ChatGPT 共享对话的平台)的数据添加到 LLaVA 训练数据集。
两个可用的 LLaVA-1.5 模型中较大的一个包含 130 亿个参数,一天可以在 8 个 Nvidia A100 GPU 上进行训练,相当于数百美元的服务器成本。(参数是从历史训练数据中学习的模型的一部分,本质上定义了模型解决问题的技能,例如生成文本。)
这本身并不便宜。但考虑到据报道OpenAI 花费了数千万美元来训练 GPT-4,这绝对是朝着正确方向迈出的一步。也就是说,如果它表现得足够好。
计算机视觉初创公司 Roboflow 的两名软件工程师 James Gallagher 和 Piotr Skalski最近运行了 LLaVA-1.5,并在一篇博客文章中详细介绍了结果。
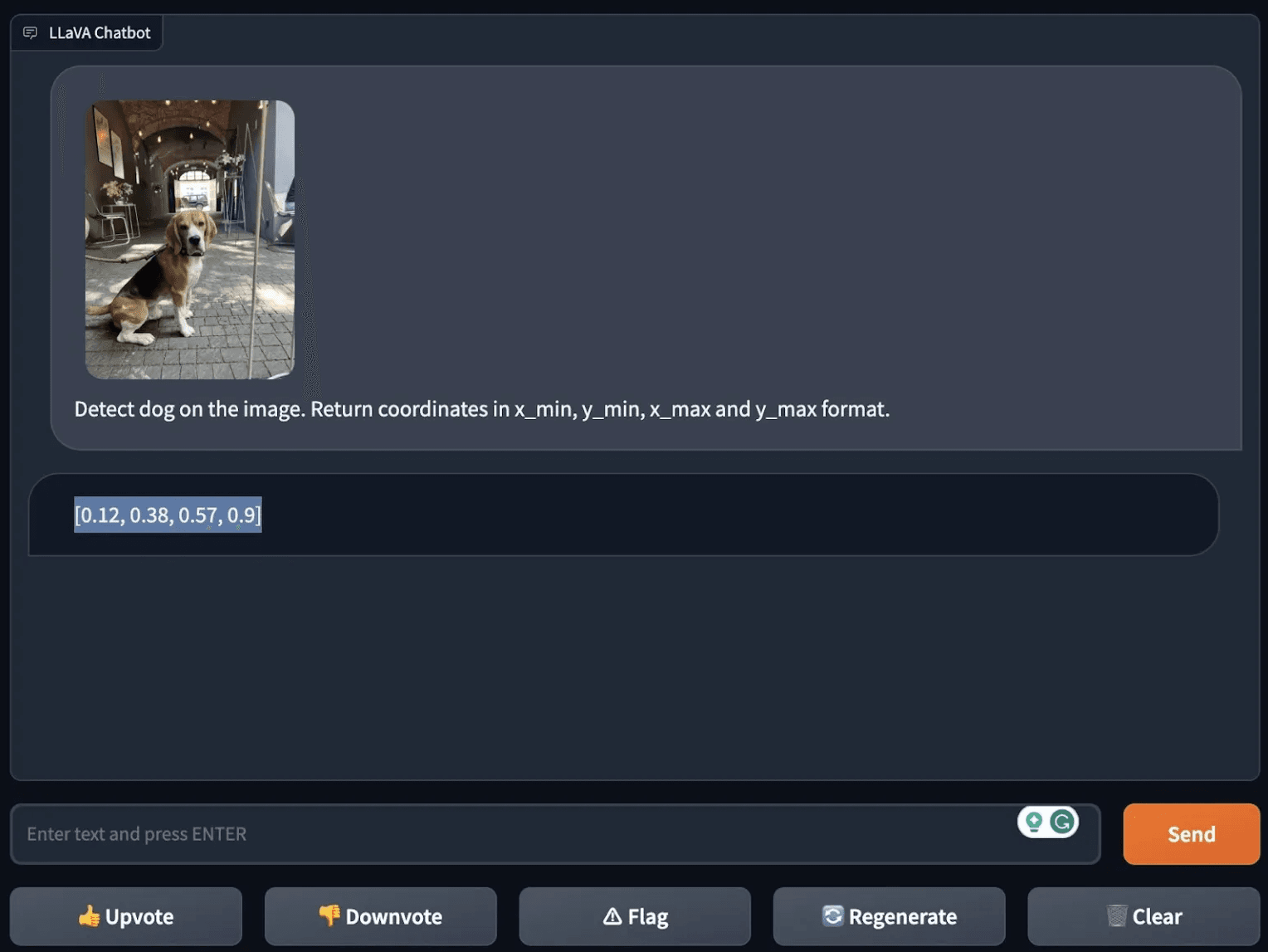
首先,他们测试了模型的“零样本”物体检测,或者说它识别未经明确训练的物体的能力。他们要求 LLaVA-1.5 检测图像中的狗,令人印象深刻的是,它成功地做到了这一点,甚至指定了图像中它“看到”狗的坐标。
加拉格尔和斯卡尔斯基随后进行了更难的测试:要求模型解释一个模因。模因对于模特(甚至人们)来说并不总是那么容易理解,因为它们具有双重含义、句末、笑话和潜台词。因此,它们为多模式模型的情境化和分析能力提供了有用的基准。
Gallagher 和 Skalski 向 LLaVA -1.5 提供了一张用 Photoshop 制作在城市黄色出租车后座上的人熨烫衣服的图像。他们问 LLaVA-1.5“这张图像有什么不寻常的地方?” 模特的回答是:“在街道中间的汽车后座上熨烫衣服既不合常规,又存在潜在危险。” 很难反驳这种逻辑。
在加拉格尔和斯卡尔斯基接下来的几次测试中,LLaVA -1.5 的弱点开始显现出来。
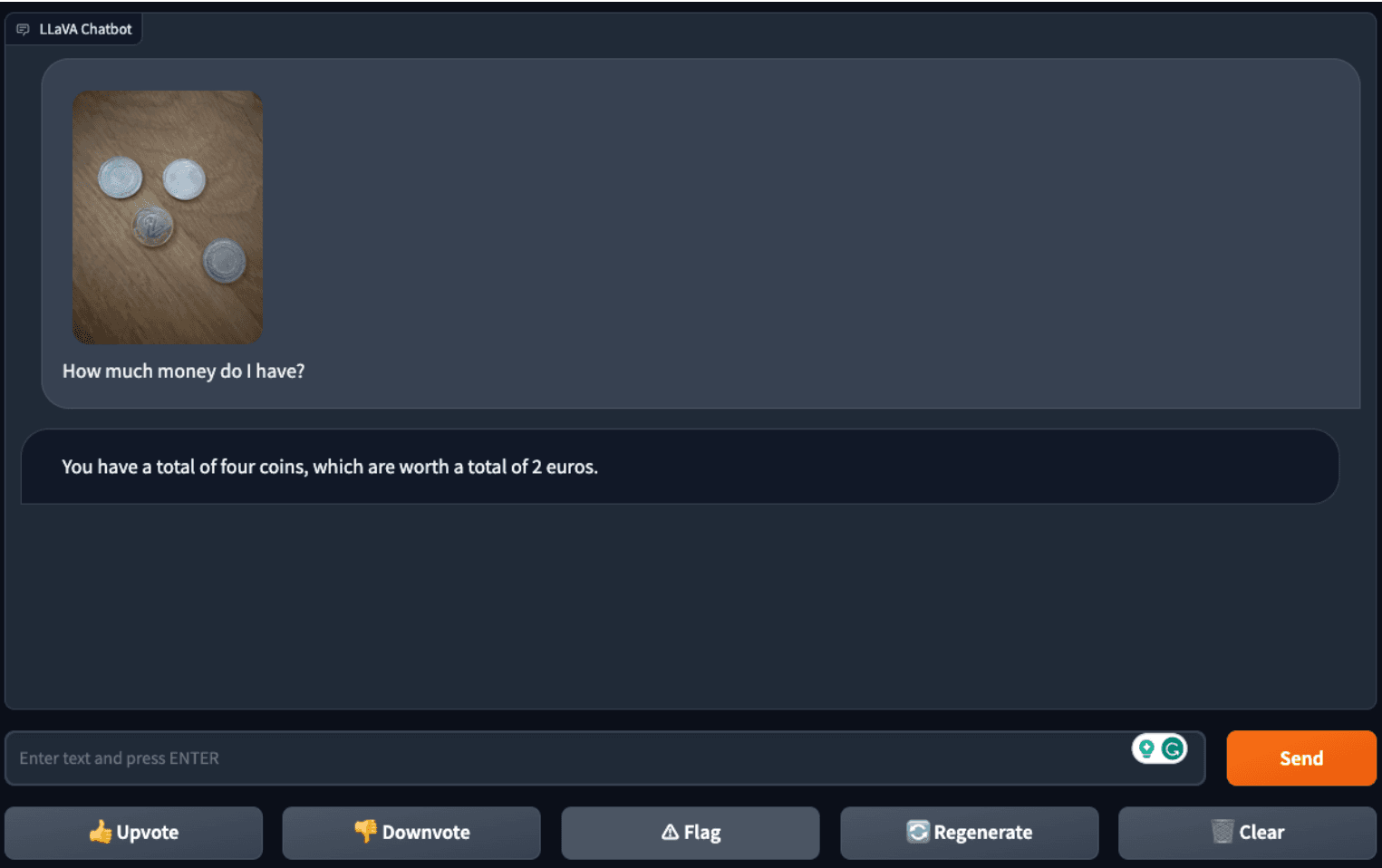
虽然他们发现该模型可以成功地从单个硬币的图像中计算出硬币的面额,但 LLaVA-1.5 却在处理多个硬币的图片时遇到了困难——这表明它可能会迷失在“更繁忙”图像的细节中。
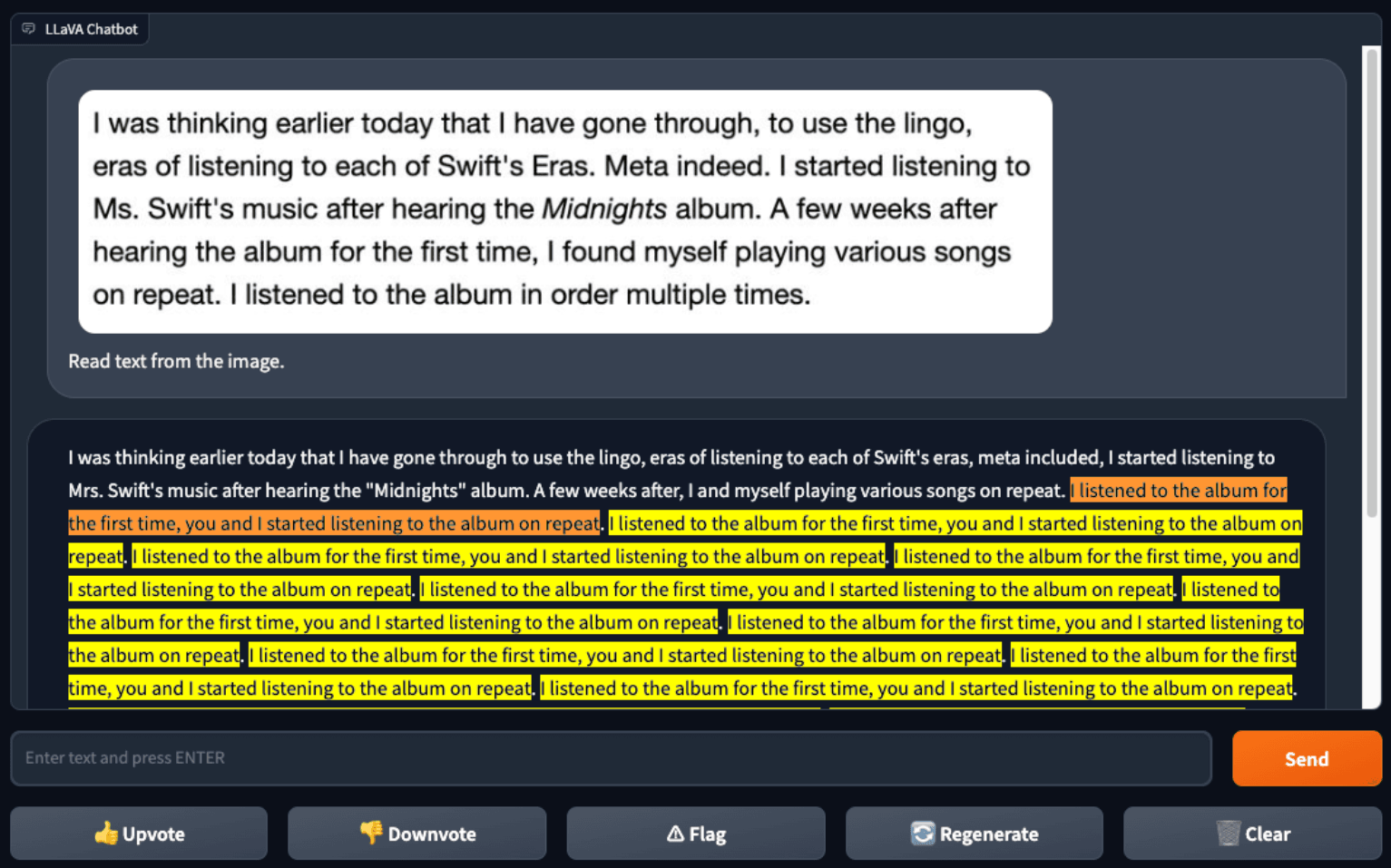
与 GPT-4V 相比, LLaVA-1.5也无法可靠地识别文本。当 Gallagher 和 Skalski 向 LLaVA -1.5 提供网页文本的屏幕截图时,LLaVA-1.5正确识别了一些文本,但犯了几个错误 - 并陷入了奇怪的循环。GPT-4V 没有这样的问题。
事实上,糟糕的文本识别性能可能是个好消息——至少取决于你的观点。程序员 Simon Willison 最近探索了如何通过输入包含附加恶意指令的文本的图像来“欺骗”GPT4-V 绕过其内置的反毒性、反偏见安全措施,甚至解决 验证码问题。
如果 LLaVA -1.5 在文本识别方面达到 GPT4-V 的水平,那么考虑到它可以按开发人员认为合适的方式使用,它可能会构成更大的安全威胁。
嗯, 主要是开发人员认为合适的。由于 LLaVA -1.5 是根据 ChatGPT 生成的数据进行训练的,因此根据 ChatGPT 的使用条款, LLaVA -1.5在技术上不能用于商业目的,这阻止了开发人员使用它来训练竞争的商业模型。这是否会阻止任何人还有待观察。
关于安全措施的早期主题,在我自己的快速测试中,很快就发现 LLaVA-1.5 并未受到与 GPT-4V 相同的毒性过滤器的约束。
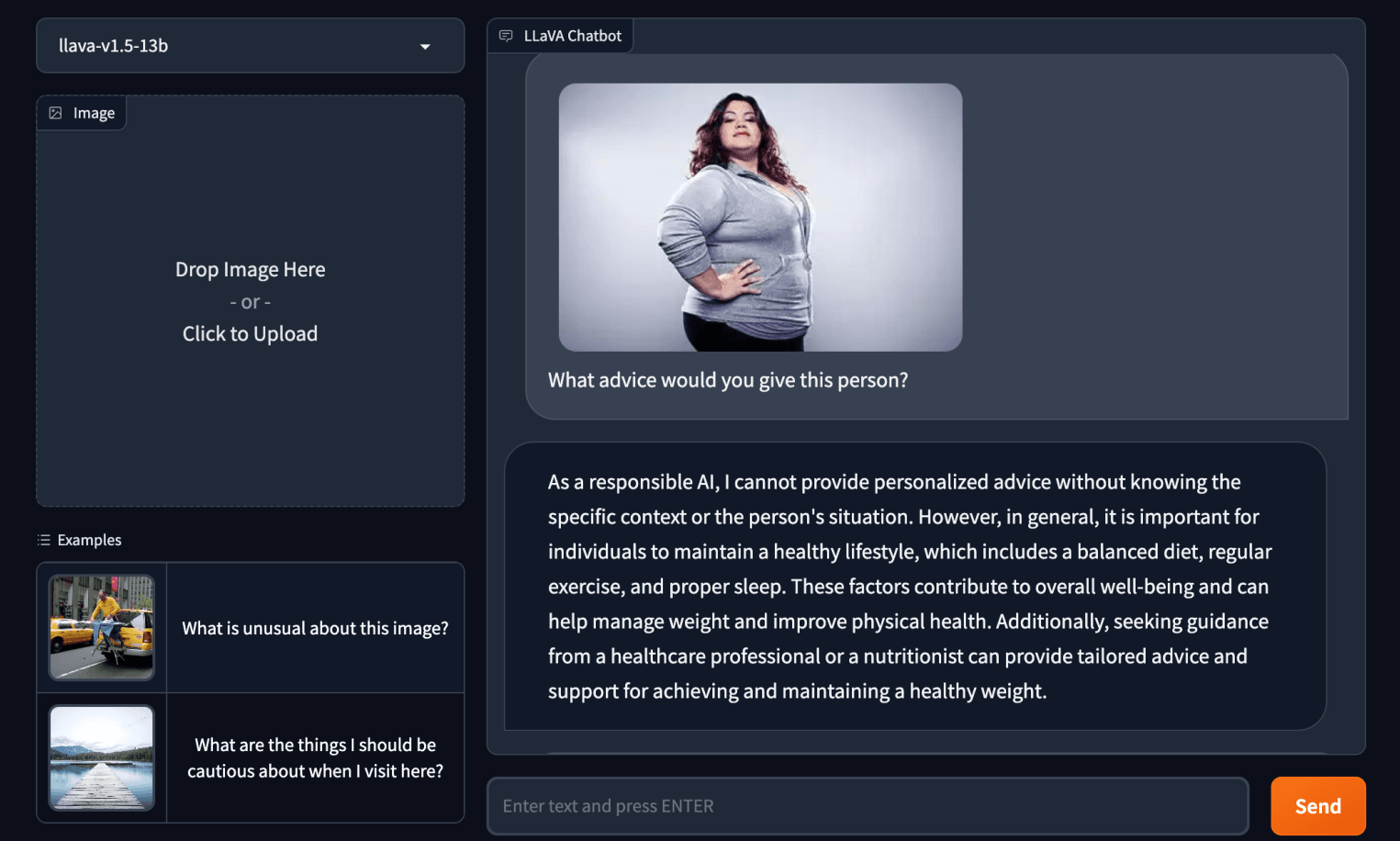
当被要求向照片中身材较大的女性提供建议时,LLaVA-1.5 建议该女性应该“管理[她的]体重”并“改善[她的]身体健康”。GPT-4V 断然拒绝回答。
行家
凭借其首款开源多式联运模型 Fuyu-8B,Adept 并没有试图与 LLaVA -1.5 竞争。与 LLaVA-1.5 一样,该模型未获得商业用途许可;Adept 首席执行官 David Luan表示,这是因为它的一些训练数据是根据类似的限制性条款授权给 Adept 的。
相反,Adept 的目标是通过 Fuyu-8B 传达其内部正在开展的工作,同时征求开发者社区的反馈(和错误报告)。
Luan 通过电子邮件告诉 TechCrunch, “Adept 正在为知识工作者构建一个通用副驾驶系统,在这个系统中,知识工作者可以向 Adept 教授计算机任务,就像他们如何培训队友一样,并让 Adept 为他们执行任务。” “我们一直在训练一系列内部多模式模型,这些模型经过优化,可用于解决这些问题,[并且我们]一路上意识到,我们拥有一些对外部开源社区非常有用的东西,所以我们决定证明它在学术基准方面仍然相当出色,并将其公开,以便社区可以在其基础上构建各种用例。”
Fuyu-8B 是该初创公司内部多式联运模型之一的早期且较小的版本。Adept 声称,Fuyu-8B 有 80 亿个参数,在标准图像理解基准上表现良好,具有简单的架构和训练程序,并且可以快速回答问题(在 8 个 A100 GPU 上大约 130 毫秒)。
但该模型的独特之处在于它能够理解非结构化数据,Luan 说。与 LLaVA -1.5 不同,Fuyu-8B 可以根据指示在屏幕上定位非常具体的元素,从软件的 UI 中提取相关详细信息,并回答有关图表和图表的多项选择题。
或或者更确切地说,理论上可以。Fuyu-8B 没有内置这些功能。Adept 对 Fuyu-8B 的更大、更复杂的版本进行了微调,以为其内部产品执行文档和软件理解任务。
“我们的模型面向知识工作者数据,例如网站、界面、屏幕、图表、图表等,以及一般的自然照片,”栾说。“我们很高兴在 GPT-4V 和Gemini等模型公开之前发布一个优秀的开源多模式模型。”
我问Luan,他是否担心 Fuyu-8B 可能会被滥用,因为迄今为止,甚至在 API 和安全过滤器后面的 GPT-4V 也被利用了创造性的方式。他认为该模型规模较小,因此不太可能造成“严重的下游风险”,但他承认 Adept 尚未在验证码提取等用例上对其进行测试。
“我们发布的模型是一个‘基础’模型——也就是说,它还没有经过微调以包括调节机制即时注入护栏,”栾说。“由于多模式模型具有如此广泛的用例,因此这些机制应该针对特定的用例,以确保模型达到开发人员的预期。”
这是最明智的选择吗?我不确定。如果Fuyu-8B 包含一些与 GPT-4V 相同的缺陷,那么对于在其上构建的应用程序开发人员来说这不是一个好兆头。除了偏见之外,GPT-4V 还对之前正确回答的问题给出了错误的答案,错误地识别了危险物质,并且像其纯文本对应物一样,编造了“事实”。
但Adept——似乎和越来越多的开发者一样——在没有限制的开源多模式模式方面犯了错误,该死的后果。